 Stan 的小屋子
Stan 的小屋子好久没有写博客了,提笔竟然不知道该怎么开头,索性就直入主题吧。最近一直做了很多分布式系统可观察性方向的 research,发现没有找到一篇能很系统性介绍的文章,在 google 了一堆资料后想自己简单的记录一些。
首先不得不提的一篇文章是 The Three Pillars of Observability。Logs、Metrics、Tracing 通常被认为是可观察性的三大支柱。Logs 是最容易理解和落地的,排查一个复杂的问题经常需要查看非常细粒度的日志消息来定位到问题所在。这里推荐结构化日志(例如 json),可以让日志在统一的日志中心里查看时更方便检索和聚合,也更容易对其做二次处理(例如监控报警)。实际上 Metrics 和 Tracing 更像是 Logs 更高级别的抽象,Metrics 聚焦于聚合和统计,Tracing 聚焦于请求级别的跨组件追踪。Logs 虽然已经足够详细了,但是在分布式系统面前,大量的跨组件调用还是会让整个排查流程不够直观,排查起来复杂无比,Tracing 在这方面的作用就极大的体现出来了。本文的重点想主要聚焦在可观察性和 Tracing 这两块,探索一些当下业内的主流方案协议以及一些工具的实现。
分布式追踪的架构组件
说起分布式追踪那我们都需要追踪哪些地方呢?一般一个现代系统的架构组成由以下几部分构成:
-
自己的应用程序和代码(不必多说)
-
第三方 Library(Redis,MongoDB,MySQL)
-
外部服务
为了实现分布式追踪从整体上监控该应用,对应的分布式追踪就需要如下四个架构组件:
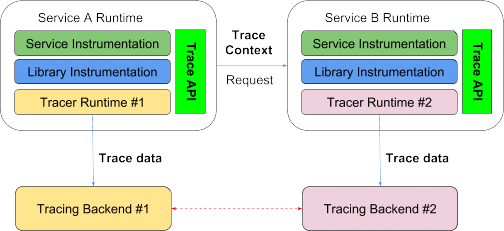
-
标准化的 tracing api:定义了代码中该以怎样的 API 来开启一次追踪。
-
标准化的 tracecontext:定义了如何跨组件传递 trace context。
-
标准化的 tracing 数据格式:定义了上报到各厂商 的 tracing 数据格式,以便各家厂商都能正确理解。
-
可互相配置的厂商 runtime:定义了各厂商必须能够通过直接修改配置将数据上报到其他厂商,以便做到百分百兼容。
接下来就需要提到 OpenTracing 了。
OpenTracing
OpenTracing 提供了一组 vendor-neutral 的 API 接口,而且支持大部分主流的编程语言(JAVA、GO、NodeJs 等9种),解决了上面提到的第一个问题。
Spec
其基本的数据模型来自 Google 的 Dapper 论文,大致结构如下:
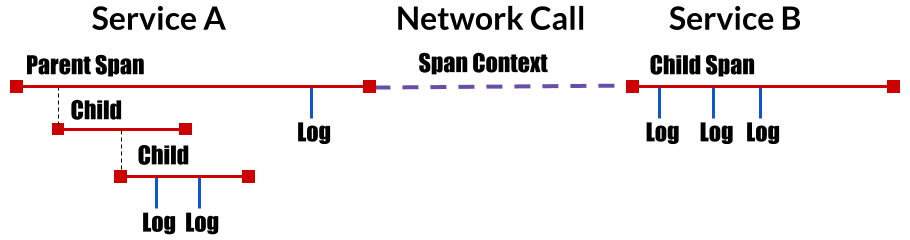
- Tracing:代表一个事务在分布式系统中移动的整个过程。本质上是一个 由 Span 构成的 DAG(有向无环图),通过 traceId 将整个过程串联起来。
- Span:一个工作单元,可以是一次数据库调用,一次外部请求调用,也可以自定义的将重要的工作通过 span 封装起来作为一次有意义的工作单元记录。一个 span 包含以下信息:
- 一个操作名称
- 起始时间戳和结束时间戳
- Tags 集合
- Logs 集合
- SpanContext
- SpanContext:spanContext 用于描述跨进程追踪时携带的数据。一个 spanContext 包含以下信息:
- 当前的 traceId(整个链路中唯一) 和 spanId(作为跨进程请求的父 span)
- 其他任意需要跨进程传递的 key-value 信息(Any Baggage Items)
- References:用于描述两个 Span 之间的引用关系,opentracing 中定义了两种父子关系。
- 第一种叫 ChildOf,比较好理解,子 Span 在启动后需要传递父 Span 的引用,并定义关系为 ChildOf,父 Span 必须在子 Span 结束前 Blocking。
- 第二种叫 FollowsFrom,父Span 不以任何形式依赖子 Span 的执行结果,比如 golang 中常见的在一次 API 请求的结束部分,起一个 goroutinue 去做一些收尾工作。
opentracing-go 的细节
TODO,有空我会补充下这里。
结论
OpenTracing 有着非常了不起的成就,它解决了整个分布式追踪架构里面的第一个问题,Trace API。但是还有很多问题没有解决。比如,虽然它提出来 SpanContext 用于描述跨进程追踪所需要携带的信息,但是没有定义 trace context 的数据格式,起码 jeager 和 elastic apm 就使用了不同的格式,这导致一旦各服务用了不用的sdk,依旧没办法完成跨服务追踪了,所幸这一部分工作由 W3C 来完成了。
TraceContext
参见W3C Distributed Tracing Work Group ,W3C 定义了标准的 tracecontext 数据格式,并标准化成为 HTTP Header 的形式进行分布式追踪。
TraceContext 的数据格式
W3C 定义的格式如下,整个 tracecontext 由 4 部分组成:
00-f109f092a7d869fb4615784bacefcfd7-5bf936f4fcde3af0-01
- Version:版本格式,
- TraceId:一个由 32 十六进制数字组成的唯一 id,全局唯一。
- SpanId:一个 16 个十六进制数字组成的唯一 id,用于作为被请求服务的父 Span。
- Flags:由 2个十六进制数字构成,当前只有一位被使用,00000001 代表采样,00000000 代表不采样。
当然使用 HTTP header 也是有风险的,比如如果经过某个 Gateway 会自动删掉了这些 Header, 就会导致整个追踪就中断了。
标准化的 Tracing 数据上报格式
很遗憾,这部分工作目前还在由 W3C 完成,不过有些开源的 tracer 都会写一些 exporter 用来将其他厂商的数据转成自己的格式。
标准化的运行时兼容
当前应该也没有哪家厂商的 agent 能够做到改改配置就将数据上报到另外一家厂商,如果想切换厂商,还是要修改 SDK。(这部分没有测试过)
符合 OpenTracing 规范的两大工具
Elastic APM
TODO,有空补充这里
CNCF Jaeger
TODO,有空补充这里
可观察性
分布式链路追踪的内容讲完了,但是在看 OpenTracing 的文档时又发现了两个新的协议叫 OpenCensus 和 OpenTelemetry。本着程序员探索的精神就又研究了一下。
OpenCensus
官方网站在此,OpenCensus 的发起者是Google,也是 Google 内部 Tracing 系统的社区版本,随后微软也宣布加入了。厉害之处在于,不像 OpenTracing 提供了一套接口,openCensus 直接提供了一套各语言具体的 agent 实现,而且在 Tracing 的基础上整合了 Metrics,还可以上报 Metrics。但是从耦合的角度来讲,显然 OpenTracing 更加通用,很多厂家都支持 OpenTracing 标准。但是双方都想统一 Tracing 的标准,于是就有了下面的一个项目 OpenTelemetry。
OpenTelemetry
OpenTelemetry 合并了 OpenTracing 和 OpenCensus。OpenTelemetry 是工具,API 和 SDK 的集合,里面包含了各语言的完整实现。当前支持 Tracing 和 Metrics,官方推荐 Tracing 的后端使用 jeager,Metrics 的后端使用 Prometheus。
OpenTelemetry 的终极目标
除了 Tracing 和 Metrics,在可观察性上还有一个重要的支柱 Logs,在完成前两个优先级后,openTelemetry 的下一步就是基于日志收集工具 Fluentd 整合 Logs,以实现可观察性的终极解决方案:Logs、Mertrics 和 Tracing 的融合!这样可以在系统内做到基于Metrics的告警发现异常,通过 Tracing 定位问题模块,再根据模块具体的日志详情定位到错误根源。
Elastic Stack
顺带想讲讲 Elastic Stack,在observability-with-the-elastic-stack文章中,Elastic 也介绍了他们的产品终极形态,与 CNCF 的 OpenTelemetry 不谋而合,他们也提到了在当前的微服务模型下,人们都是利用不同的工具来处理这三类信息,在问题出现后,开发人员不得不在各种监控工具来回横跳,十分影响效率。Elastic 所要做的就是基于 ELK 和 Elastic APM 这套技术栈,实现 Logs,Metrics,Tracing 数据的收集和展示,能够在一个页面内实现 Logs,Metrics,Tracing 的互相定位,能够大大提高各种监控上下文的利用率。
开心,终于写完了,下一篇博客想写几个演示的 demo 展示下。